Probably_POTUS: A Twitter bot using ML to detect tweets written by Trump
That got me thinking...what if we didn't know which device the tweet came from, maybe we could use Machine Learning to predict which device it would have come from, thereby predicting who composed it. Why wouldn't we know which device it came from? Because Donald Trump was about to become president and there was no way they'd let him continue to tweet from his insecure personal phone, right?
EDIT: It turns out President Trump is defying all common sense and continuing to tweet with his personal Android. Should he eventually decide to listen to the 90 bajillion cybersecurity experts who think this is a terrible idea, then the rest of this blog post will be super relevant.
Anyway, this is a fairly well-posed supervised learning problem: using Trump's tweets before he took office, can we learn a set of rules that classify whether a tweet was sent by his Android or not? We can build up a set of training data whose labels will be whether or not the tweet was sent from an Andriod, which we know used to map fairly well to whether the tweet was actually written by Trump. We can use the text of the tweet and some other metadata to build features. Our model will automatically learn a set of rules to determine how the features map to the class labels. Once we have a model, we can build a Twitter bot to retweet statuses that the model is confident were written by Trump.
Eating your broccoli first
Before we get to the fun part of modeling, we have to do some engineering work. First, we need to build up our training set. To do this, I'll follow an ELT (Extract, Load, Transform...the order isn't a mistake) framework, using a PostgreSQL database to store my data for easy retrieving later.
For the Extract portion, I need to get my hands on some realDonaldTrump tweets. Twitter has a REST API that anyone can connect to in order to query tweets, and there's an excellent python library called tweepy that abstracts away much of the dirty work so you can focus on writing python instead of forming HTTP requests. My TweetExtractor class uses tweepy to query Twitter's API for a few thousand Trump tweets and saves them to disk. "Load" refers to the act of loading this data from flat files into the database I have running on an instance of Amazon's EC2 platform. I tend to keep the Load step simple, not worrying about data types and just bringing everything into the database as raw text. Since this is something I do a lot of, I have some wrappers that make this task relatively painless for small-ish data sets. Finally, SQL scripts in the Transform step make sure that data types are correct in addition to performing some lightweight feature engineering--building features that might be useful to the model (e.g. how many characters the tweet contains, how many uppercase substrings, the number of exclamation points, etc.).
The fun part
OK, now we're ready to build the model...well, almost. First we need to work on converting the features into a more useful form. We're dealing with both text data (the actual content of the tweets) as well as numerical data (character counts, # of retweets, etc) so I need to split the feature transformations steps into separate pipelines for each type of feature (more on that later).Let's start with the text data first. The first problem to solve is how to represent unstructured text as a coherent set of features so that we can build a model. I'll follow a classic Natural Language Processing (NLP) pattern called the Bag of Words model. This representation builds up a vocabulary from all of the tweets, and converts each tweet into a vector of ones and zeros indicating which words are contained in the tweet. We can go one step beyond this simple model by using Term-frequency--Inverse document frequency (Tf-Idf) weighting to assign more weight to words that occur in fewer tweets while down-weighting common words like "the" or "a" that just add to the noise.
This sounds promising, but we're getting ahead of ourselves a bit. We need to build up a Bag of Words representation, but we don't have a set of words just yet--we have tweets. We first need to figure out a way to parse our tweets to extract words from them. You might think this is as trivial as
str.split(' '), but there's more to it than that. We need to deal with punctuation as well as the fact that tweets are not the same as plain text. We need to process emojis, hashtags, and 13-year-old-girlspeak. It's a good thing the powerful NLTK library has a built-in TweetTokenizer class that does all of this for you! Tokenizers like this are built off of a set of well-established heuristics that work pretty well out of the box. Still, I helped it out a little by writing a regex to map all urls to one distinct token in our vocabulary. There's one more choice we should make about our Bag of Words implementation, and that's whether to use single words, or extend it to N-grams (collections of commonly co-occuring phrases). I actually don't have much of an opinion here, so I let the model decide. That is, I treated the value of N as a hyperparameter to the model and searched for the value that maximizes the model accuracy (it turns out, single words are better).
That's all the pre-processing for the text features, now we turn to the numeric features. Honestly, this is pretty straightforward. Because we're using a limited set of features from Twitter data, it's nice and clean with no missing values to impute, outliers to clip, or categorical features to one-hot encode. The only thing I decided to do, although it's not strictly necessary with the Random Forest model I went with, was perform min-max scaling so the numeric features were in the same range as the tf-idf-transformed text features.
For the actual estimator, I went with a Random Forest. model. So-called ensemble methods do a pretty good job at limiting overfitting, and that's something I'm a little concerned about since my feature set is rather large (determined by the size of @realDonaldTrump's vocabulary, which is...bigger than you'd think). I let cross validation pick the appropriate number of trees to build and left the other model parameters set at their (reasonable) stock values.
To put it all together, I took advantage of scikit-learn's supremeley useful Pipeline and FeatureUnion classes. These do exactly what you think they'd do: they wrap your entire ML pipeline, including pre-processing steps, into a single object. To make this even more useful, the GridSearchCV class takes as input your model Pipeline as well as a dictionary of hyperparameter values and automatically handles the cross validation to tune them. In this case, I used 5-fold stratified CV--fully specified in about 5 lines of code. What's more, scikit-learn will handle multi-threading for you so your CV loops run in parallel, stealing all of your CPU cores if you let it.
So, how well did we do? The accuracy in both the validation and test sets is at around 90%--not bad! Now that we have used the test set to get an estimate for the accuracy, there's no reason to exclude it any longer so I feed it back in to the training set and re-train the model with the best-fitting set of parameters.
Deploying a Twitter bot
Inspired by @RealRealDonaldT, I decided to make a Twitter bot to re-tweet all the statuses that the model believes were written by Trump. The difference between my bot and theirs is that mine makes a decision based on the tweet itself, and doesn't use the device type in its decision. Instead, it learned how to recognize the device from the language of the tweet.To process tweets in real time as they come in, I needed to connect to Twitter's streaming API. Unlike the ETL I built for processing the training data, I needed the real-time data pipeline to be simple and fast. The solution I came upon is described in the diagram below. Instead of writing new tweets to the database, I bypass it completely and perform the transform steps in-memory on pandas Dataframes. That's a bit of a DRY violation since I had to write transform code twice (once in SQL and once in python), but it makes things much simpler when dealing with a streaming process.
 |
| Digram of the data flow. |
With my new pipeline sketched out, it was pretty straightforward to code up a handler to listen for incoming tweets, transform them, and re-tweet any statuses the model thinks are really from Trump. I deployed everything to an EC2 instance, loaded a serialized model (so the feature processing Pipeline came along for free) and just waited for Donald Trump to get in a bad mood.
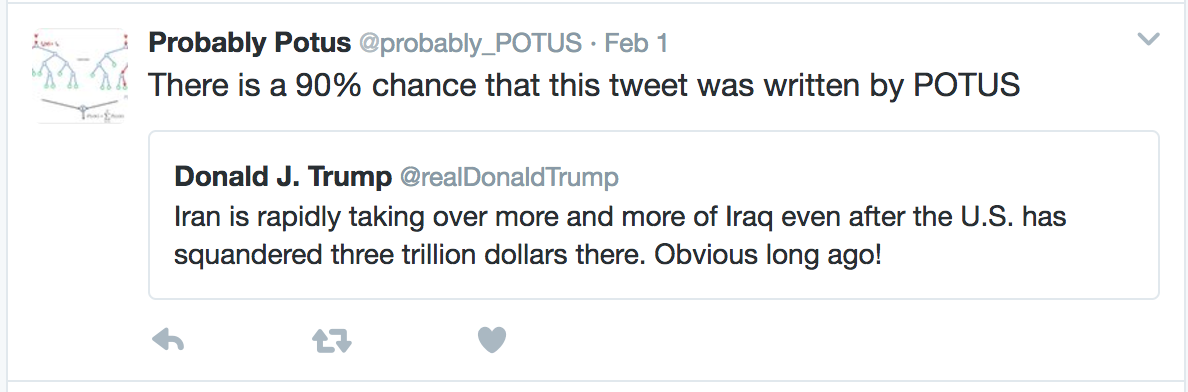 |
| Success! |
The bot has been running for a few days now and it seems to be working pretty well. There are a few issues I'd like to tackle to improve it, so I'll probably keep tweaking it for some time. In the meantime, follow along with @Probably_POTUS. Be careful, though...these tweets are the craziest of the crazy.
The entire code for this project can be found on GitHub. Feedback or PRs are more than welcome!
Leave a Comment